架构
Kafka Streams 基于 Kafka 生产者和使用者库构建,并利用 Kafka 提供数据并行性、分布式协调、容错和作简单性。在本节中,我们将介绍 Kafka Streams 的工作原理。下图显示了使用 Kafka Streams 库的应用程序的剖析。让我们来了解一些细节。

Stream 分区和任务
Kafka 的消息收发层对数据进行分区,以便存储和传输数据。Kafka Streams 对数据进行分区以进行处理。 在这两种情况下,这种分区都是实现数据局部性、弹性、可扩展性、高性能和容错能力的原因。 Kafka Streams 使用分区和任务的概念作为其基于 Kafka 主题分区的并行模型的逻辑单元。 在并行性上下文中,Kafka Streams 和 Kafka 之间存在密切联系:
- 每个流分区都是一个完全有序的数据记录序列,并映射到 Kafka 主题分区。
- 流中的数据记录映射到来自该主题的 Kafka 消息。
- 数据记录的键决定了 Kafka 和 Kafka Streams 中的数据分区,即数据如何路由到 topic 内的特定分区。
通过将应用程序的处理器拓扑分解为多个任务来扩展应用程序。 更具体地说,Kafka Streams 根据应用程序的 input 流分区创建固定数量的任务。 为每个任务分配一个来自输入流(即 Kafka 主题)的分区列表。将分区分配给任务 永不更改,以便每个任务都是应用程序的固定并行单元。然后,任务可以实例化自己的处理器拓扑 基于分配的分区;他们还为每个分配的分区维护一个缓冲区,并一次处理一个消息 这些记录缓冲区。因此,流任务可以独立并行处理,无需人工干预。
稍微简化一下,应用程序可以运行的最大并行度受最大流任务数的限制,而流任务数本身由 应用程序正在从中读取的输入主题的最大分区数。例如,如果您的输入主题有 5 个分区,则最多可以运行 5 个 applications 实例。这些实例将协作处理主题的数据。如果您运行的应用程序实例数多于输入的分区数 topic,则 “excess” 应用程序实例将启动但保持空闲状态;但是,如果其中一个繁忙的实例宕机,其中一个空闲实例将恢复前者的 工作。
重要的是要了解 Kafka Streams 不是一个资源管理器,而是一个库,它可以“运行”在流处理应用程序运行的任何位置。 应用程序的多个实例可以在同一台计算机上执行,也可以分布在多台计算机上,并且可以自动分配任务 通过库传递给那些正在运行的应用程序实例。对任务的分区分配永远不会改变;如果应用程序实例失败,则其分配的所有 任务将在其他实例上自动重启,并继续使用来自同一流分区的 Task。
注意:主题分区分配给任务,并将任务分配给所有实例上的所有线程,以尽最大努力 在负载均衡和有状态任务的粘性之间进行权衡。对于此分配,Kafka Streams 使用 StreamsPartitionAssignor 类,并且不允许您更改为其他分配器。如果您尝试使用不同的分配器,Kafka Streams 会忽略它。
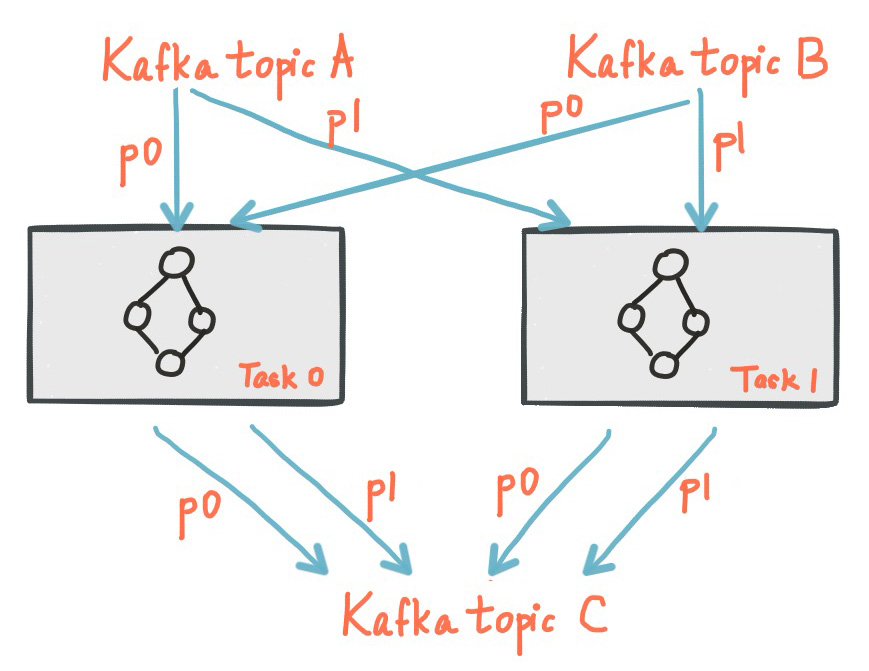
下图显示了两个任务,每个任务都分配有输入流的一个分区。
线程模型
Kafka Streams 允许用户配置库可用于在应用程序实例中并行处理的线程数。 每个线程都可以独立执行一个或多个具有其处理器拓扑的任务。例如,下图显示了一个运行两个流任务的流线程。

启动应用程序的更多流线程或更多实例仅相当于复制拓扑并让它处理 Kafka 分区的不同子集,从而有效地并行化处理。 值得注意的是,线程之间没有共享状态,因此不需要线程间协调。这使得跨应用程序实例和线程并行运行拓扑变得非常简单。 Kafka Streams 利用 Kafka 的协调功能,透明地处理各种流线程之间 Kafka 主题分区的分配。
正如我们上面所描述的,使用 Kafka Streams 扩展您的流处理应用程序很容易:您只需要启动应用程序的其他实例。 Kafka Streams 负责在应用程序实例中运行的任务之间分配分区。您可以启动应用程序的任意数量的线程 因为有输入 Kafka 主题分区,因此,在应用程序的所有运行实例中,每个线程(或者更确切地说,它运行的任务)至少有一个输入分区要处理。
从 Kafka 2.8 开始,您可以像扩展 Kafka Stream 客户端一样扩展流线程。 只需添加或删除流线程,Kafka Streams 就会负责重新分配分区。 您还可以添加线程来替换已死亡的流线程,无需重新启动客户端来恢复正在运行的线程数。
本地 State Store
Kafka Streams 提供了所谓的状态存储,流处理应用程序可以使用它来存储和查询数据。
这是实现有状态作时的一项重要功能。例如,Kafka Streams DSL 会自动创建
并在您调用有状态运算符(例如 or )或对流进行窗口化时管理此类状态存储。join()aggregate()
Kafka Streams 应用程序中的每个流任务都可以嵌入一个或多个本地状态存储,这些状态存储可以通过 API 访问,以存储和查询处理所需的数据。 Kafka Streams 为此类本地状态存储提供容错和自动恢复功能。
下图显示了两个流任务及其专用的本地 state store。

容错
Kafka Streams 基于 Kafka 中原生集成的容错功能构建。Kafka 分区具有高可用性和可复制性;因此,当流数据持久化到 Kafka 时,它是可用的 即使应用程序失败并需要重新处理它。Kafka Streams 中的任务利用容错功能 由 Kafka Consumer Client 提供,用于处理故障。 如果任务在发生故障的计算机上运行,Kafka Streams 会自动在应用程序的剩余运行实例之一中重新启动该任务。
此外,Kafka Streams 还确保本地状态存储对故障也很健壮。对于每个状态存储,它维护一个复制的 changelog Kafka 主题,并在其中跟踪任何状态更新。 这些 changelog 主题也被分区,以便每个本地 state store 实例以及访问该 store 的任务都有自己专用的 changelog 主题分区。在 changelog 主题上启用了日志压缩,以便可以安全地清除旧数据,以防止主题无限增长。 如果任务在发生故障的机器上运行并在另一台机器上重新启动,则 Kafka Streams 保证通过以下方式将其关联的状态存储恢复到发生故障之前的内容 在恢复对新启动的任务的处理之前重放相应的 changelog 主题。因此,故障处理对最终用户是完全透明的。
请注意,任务(重新)初始化的成本通常主要取决于通过重放状态存储的关联更改日志主题来恢复状态的时间。
为了最大限度地缩短此还原时间,用户可以将其应用程序配置为具有本地状态的备用副本(即状态的完全复制副本)。
当任务迁移发生时,Kafka Streams 会将任务分配给已经存在此类备用副本的应用程序实例,以最小化
任务(重新)初始化成本。请参阅 Kafka Streams 配置部分。
从 2.6 开始,Kafka Streams 将保证仅将任务分配给具有完全捕获的状态本地副本的实例,如果此类实例
存在。备用任务将增加在发生故障时存在 caught up 实例的可能性。num.standby.replicas
您还可以配置具有机架感知功能的备用副本。配置后,Kafka Streams 将尝试
将备用任务分布在与活动任务不同的“机架”上,因此在
活动任务的 rack 失败。请参阅 Kafka Streams 开发人员指南 部分。rack.aware.assignment.tags
还有一个客户端配置,可以为 Kafka 使用者设置机架。如果 broker 也通过 设置了机架,则机架感知任务
可以通过(参见 Kafka Streams 开发人员指南)来启用分配来计算任务分配,该任务分配可以通过尝试将任务分配给具有相同机架的客户端来减少跨机架流量。
请注意,还可用于将备用任务分发到与活动任务不同的机架,其功能与 .
目前,在分发备用任务时优先,这意味着如果两个配置都存在,将用于分发
standby 任务与活动机架位于不同的机架上,因为它可以配置更多的标签键。client.rackbroker.rackrack.aware.assignment.strategyclient.rackrack.aware.assignment.tagsrack.aware.assignment.tagrack.aware.assignment.tag