运行 Kafka Streams 演示应用程序
本教程假设您从头开始,并且没有现有的 Kafka 或 ZooKeeper 数据。但是,如果您已经启动了 Kafka,请随时跳过前两个步骤。
Kafka Streams 是一个客户端库,用于构建任务关键型实时应用程序和微服务。 其中,输入和/或输出数据存储在 Kafka 集群中。Kafka Streams 结合了 在客户端编写和部署标准 Java 和 Scala 应用程序,并利用 Kafka 的 服务器端集群技术,使这些应用程序具有高度可扩展性、弹性、容错性、分布式、 以及更多。
此快速入门示例将演示如何运行在此库中编码的流式处理应用程序。要点如下
示例代码(转换为使用 Java 8 lambda 表达式,以便于阅读)。WordCountDemo
// Serializers/deserializers (serde) for String and Long types
final Serde<String> stringSerde = Serdes.String();
final Serde<Long> longSerde = Serdes.Long();
// Construct a `KStream` from the input topic "streams-plaintext-input", where message values
// represent lines of text (for the sake of this example, we ignore whatever may be stored
// in the message keys).
KStream<String, String> textLines = builder.stream(
"streams-plaintext-input",
Consumed.with(stringSerde, stringSerde)
);
KTable<String, Long> wordCounts = textLines
// Split each text line, by whitespace, into words.
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
// Group the text words as message keys
.groupBy((key, value) -> value)
// Count the occurrences of each word (message key).
.count();
// Store the running counts as a changelog stream to the output topic.
wordCounts.toStream().to("streams-wordcount-output", Produced.with(Serdes.String(), Serdes.Long()));它实现了 WordCount algorithm,它根据输入文本计算单词出现直方图。但是,与其他 WordCount 示例不同 您之前可能已经看到对有界数据进行作,WordCount 演示应用程序的行为略有不同,因为它 旨在对无限的无限数据流进行作。与有界变体类似,它是一个有状态算法, 跟踪和更新字数。但是,由于它必须假设潜在的 unbound的 input 数据,它会周期性地输出其当前状态和结果,同时继续处理更多数据 因为它无法知道何时处理了 “所有” 输入数据。
作为第一步,我们将启动 Kafka(除非您已经启动了它),然后我们将 准备 Kafka 主题的输入数据,该主题随后将由 Kafka Streams 应用程序处理。
第 1 步:下载代码
下载 {{fullDotVersion}} 版本并解压。 请注意,有多个可下载的 Scala 版本,我们在此处选择使用推荐的版本 ({{scalaVersion}}):$ tar -xzf kafka_{{scalaVersion}}-{{fullDotVersion}}.tgz
$ cd kafka_{{scalaVersion}}-{{fullDotVersion}}第 2 步:启动 Kafka 服务器
Apache Kafka 可以使用 ZooKeeper 或 KRaft 启动。要开始使用任一配置,请遵循以下部分之一,但不能同时执行这两部分。
带有 ZooKeeper 的 Kafka
运行以下命令以按正确顺序启动所有服务:
$ bin/zookeeper-server-start.sh config/zookeeper.properties打开另一个终端会话并运行:
$ bin/kafka-server-start.sh config/server.properties带有 KRaft 的 Kafka
生成集群 UUID
$ KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"设置日志目录的格式
$ bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c config/kraft/server.properties启动 Kafka 服务器
$ bin/kafka-server-start.sh config/kraft/server.properties第 3 步:准备输入主题并启动 Kafka 生产者
接下来,我们创建名为 streams-plaintext-input 的输入主题和名为 streams-wordcount-output 的输出主题:注意:我们在启用压缩的情况下创建输出主题,因为输出流是 changelog 流 (参见下面的应用程序输出说明)。 创建的主题可以使用相同的 kafka-topics 工具进行描述:$ bin/kafka-topics.sh --create \
--bootstrap-server localhost:9092 \
--replication-factor 1 \
--partitions 1 \
--topic streams-plaintext-input
Created topic "streams-plaintext-input".$ bin/kafka-topics.sh --create \
--bootstrap-server localhost:9092 \
--replication-factor 1 \
--partitions 1 \
--topic streams-wordcount-output \
--config cleanup.policy=compact
Created topic "streams-wordcount-output".$ bin/kafka-topics.sh --bootstrap-server localhost:9092 --describe
Topic:streams-wordcount-output PartitionCount:1 ReplicationFactor:1 Configs:cleanup.policy=compact,segment.bytes=1073741824
Topic: streams-wordcount-output Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic:streams-plaintext-input PartitionCount:1 ReplicationFactor:1 Configs:segment.bytes=1073741824
Topic: streams-plaintext-input Partition: 0 Leader: 0 Replicas: 0 Isr: 0第 4 步:启动 Wordcount 应用程序
以下命令启动 WordCount 演示应用程序:$ bin/kafka-run-class.sh org.apache.kafka.streams.examples.wordcount.WordCountDemo演示应用程序将从输入主题 streams-plaintext-input 中读取,对每条读取的消息执行 WordCount 算法的计算, 并持续将其当前结果写入输出主题 streams-wordcount-output。 因此,除了日志条目之外,不会有任何 STDOUT 输出,因为结果在 Kafka 中写回去。
现在,我们可以在单独的终端中启动控制台创建器,以将一些输入数据写入此主题:并通过在单独的终端中使用控制台使用者读取其输出主题来检查 WordCount 演示应用程序的输出:$ bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic streams-plaintext-input$ bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic streams-wordcount-output \
--from-beginning \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer第 5 步:处理一些数据
现在,让我们通过输入一行文本,然后点击 <RETURN>,与控制台创建者一起将一些消息写入输入主题 streams-plaintext-input 中。 这将向输入主题发送一条新消息,其中 message 键为 null,消息值是您刚刚输入的字符串编码文本行 (在实践中,应用程序的输入数据通常会持续流式传输到 Kafka,而不是像本快速入门中那样手动输入):$ bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic streams-plaintext-input
>all streams lead to kafka此消息将由 Wordcount 应用程序处理,以下输出数据将写入 streams-wordcount-output 主题并由控制台使用者打印:
$ bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic streams-wordcount-output \
--from-beginning \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
all 1
streams 1
lead 1
to 1
kafka 1在这里,第一列是格式的 Kafka 消息键,表示正在计数的单词,第二列是格式的消息值,表示单词的最新计数。java.lang.Stringjava.lang.Long
$ bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic streams-plaintext-input
>all streams lead to kafka
>hello kafka streams$ bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic streams-wordcount-output \
--from-beginning \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
all 1
streams 1
lead 1
to 1
kafka 1
hello 1
kafka 2
streams 2$ bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic streams-plaintext-input
>all streams lead to kafka
>hello kafka streams
>join kafka summit$ bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic streams-wordcount-output \
--from-beginning \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
all 1
streams 1
lead 1
to 1
kafka 1
hello 1
kafka 2
streams 2
join 1
kafka 3
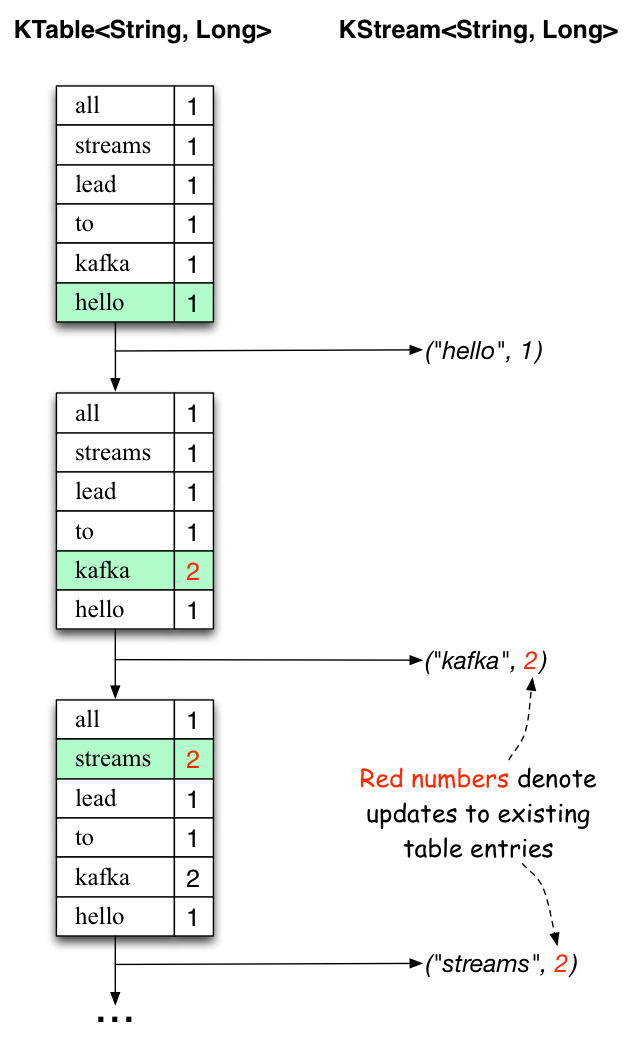
summit 1下面的两个图表说明了幕后发生的事情。
第一列显示了 的当前状态的演变,即对 的单词出现次数进行计数。
第二列显示 KTable 状态更新产生的更改记录,这些记录被发送到输出 Kafka 主题 streams-wordcount-output。KTable<String, Long>count
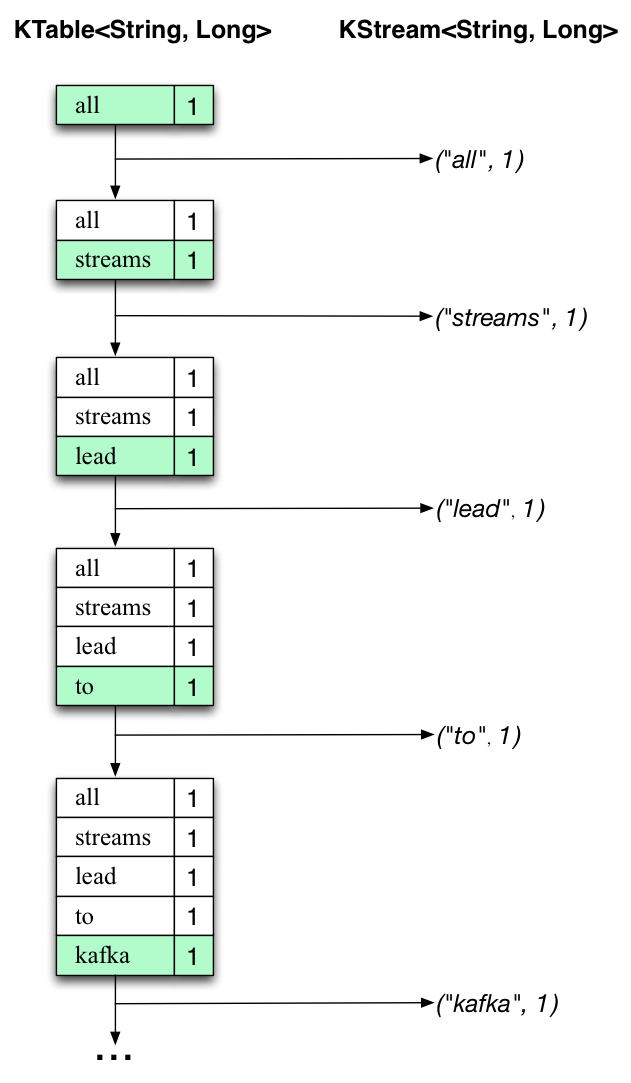
首先,正在处理文本行 “all streams leads to kafka”。
由于每个新单词都会生成一个新的表条目(以绿色背景突出显示),并且相应的更改记录将发送到下游。KTableKStream
当处理第二行文本 “hello kafka streams” 时,我们第一次观察到 中的现有条目正在更新(此处:对于单词 “kafka” 和 “streams”)。同样,更改记录被发送到输出主题。KTable
依此类推(我们跳过如何处理第三行的插图)。这就解释了为什么 output topic 具有我们上面显示的内容,因为它包含了 changes 的完整记录。
除了这个具体示例的范围之外,Kafka Streams 在这里所做的是利用表和 changelog 流之间的对偶性(这里:table = KTable,changelog 流 = 下游 KStream):你可以将表的每个更改发布到一个流中,如果你从头到尾使用整个 changelog 流, 您可以重建 table 的内容。
第 6 步:拆解应用程序
现在,您可以通过 Ctrl-C 按顺序停止控制台使用者、控制台创建者、Wordcount 应用程序、Kafka 代理和 ZooKeeper 服务器(如果已启动)。